Message Passing Multi-Agent Generative Adversarial Networks
Arnab Ghosh*, Viveka Kulharia*, Vinay Namboodiri
*Equal contribution
The Crux
We introduce a message passing framework in Generative Adversarial Networks whereby the generations are conditioned on the message it receives from the analysis of the other generator.
We introduce an Objective where the Generators compete with each other to get better scores for its generations from the Discriminator apart from just maximally fooling the discriminator.
We introduce an Objective where the Generators co-operate and encourage the other generator to get better scores for its generations from the Discriminator apart from just maximally fooling the discriminator.
We show for the first time two Generators generating images conditioned on totally different noise distributions.
Interesting Differences in Generations by the two Generators

Generations of Generator 1 with uniform(-1,1) noise distribution with conditioned message passing. It captures detailed facial expressions.

Generations of Generator 2 with N(0,1) noise distribution with conditioned message passing. It captures smooth features of facial expression.
Artistic Creation

Generations look as if showing the process of artist creation. The generations were created using a message interpolation by keeping the noise constant and varying the message between the 2 messages. It shows that the message space is also continuous.
The Best Performing Model
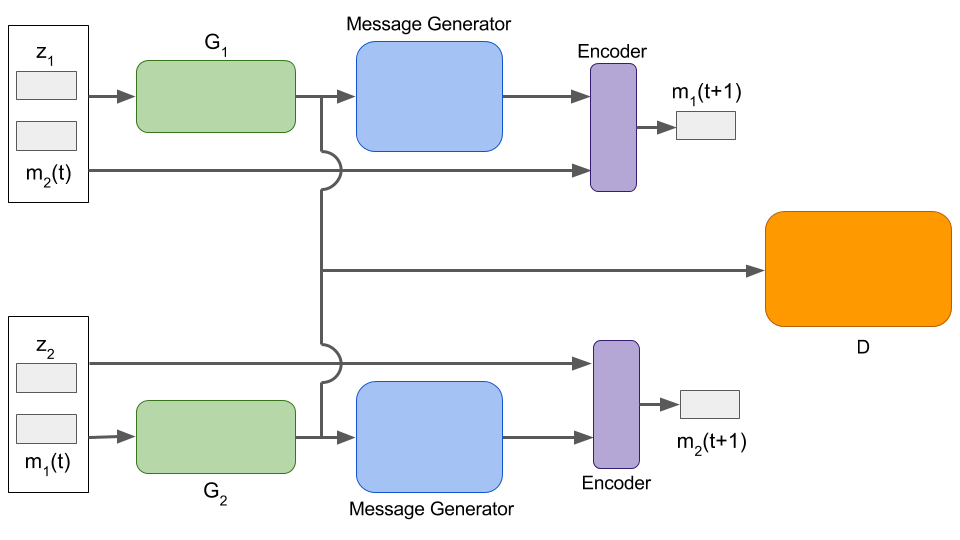
Salient Features
A common Message Generator looks at the input to the generators and their respective outputs and generates a message to be passed to the other generator.
Each Generator generates images conditioned on noise and message received from the analysis of the other generator.
Results and Analysis
Classification Results
- The images were passed through the discriminator and the message generator to get the representation from the activations of the hidden layers as was used by DCGAN Radford et al. (2015).
| Model | Discriminator Rep | Message Rep | Msg+Disc Rep |
|---|---|---|---|
| DCGAN Radford et al. (2015) | 22.48% | NA | NA |
| Improved GANs Salimans et al. (2016) | 8.11 ± 1.3 % | NA | NA |
| Different Noise MP | 20.1% | 53.48% | 18.7% |
| Different Noise CMP | 17.1% | 54.21% | 15.2% |
| Conceding CMP | 18.37% | 64.46% | 17.4% |
| Competing CMP | 17.76% | 52.05% | 16.8% |
| Competing Objective | 18.02% | NA | NA |
| Conceding Objective | 17.56% | NA | NA |
As shown in the Table all of the models’ discriminator representation improved the results over the discriminator representation of DCGAN Radford et al. (2015) thus showing that the proposed models provide regularization to the training procedure of the discriminator.
The non-trivial accuracy obtained by the message representation which never got to see the real images is an interesting phenomena while the improvement of the accuracy with the represenation consisting of Message along-side the Discriminator features shows that the Message representation learns some complementary features which helps in the overall classification task.
Message Clustering
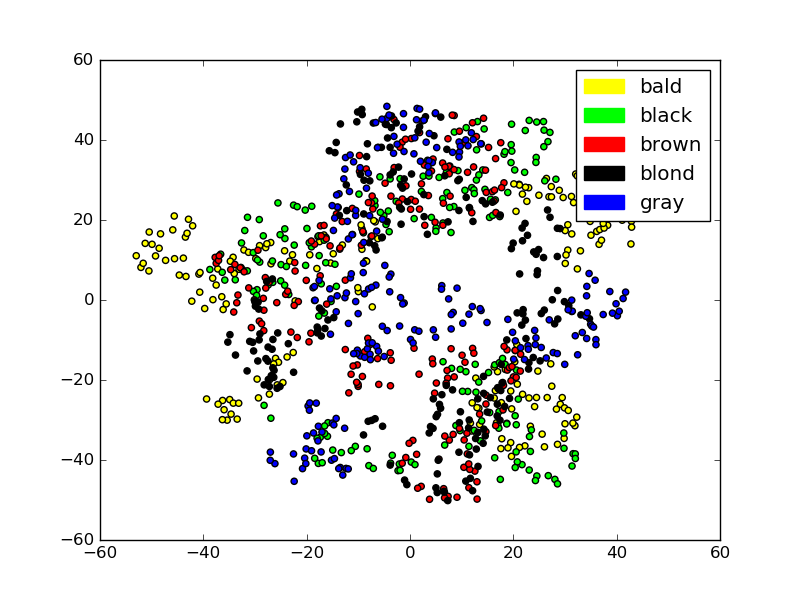
The celebrity dataset Liu et al. (2015) was used to partition the faces based on the type of hair into five categories: bald, black, brown, blond and gray.
The images belonging to these partitions were passed through the Message Generator to get the representations of each of the images from the Message Generator.
The representations are then reduced to 2 dimensions using T-SNE and then they are represented using the different colors.
The messages for the bald hair style totally separates from the rest while black and brown being a bit subjective are similar in the message space but some clusters for black hair emerge which are totally pure.
Gray hair also separates quite clearly from the rest.
Some Interesting Interpolation Results

This is a perfect rendering of the creation that an artist takes in order to create a masterpiece applying changes one layer at a time

The generations move from a cartoon-like representation of the woman to the actual face of the woman.

The generations move from a human to angel/spirit like representation

The classic example of depiction of ageing process. It depicts the various stages of aging of a person.